Java集合
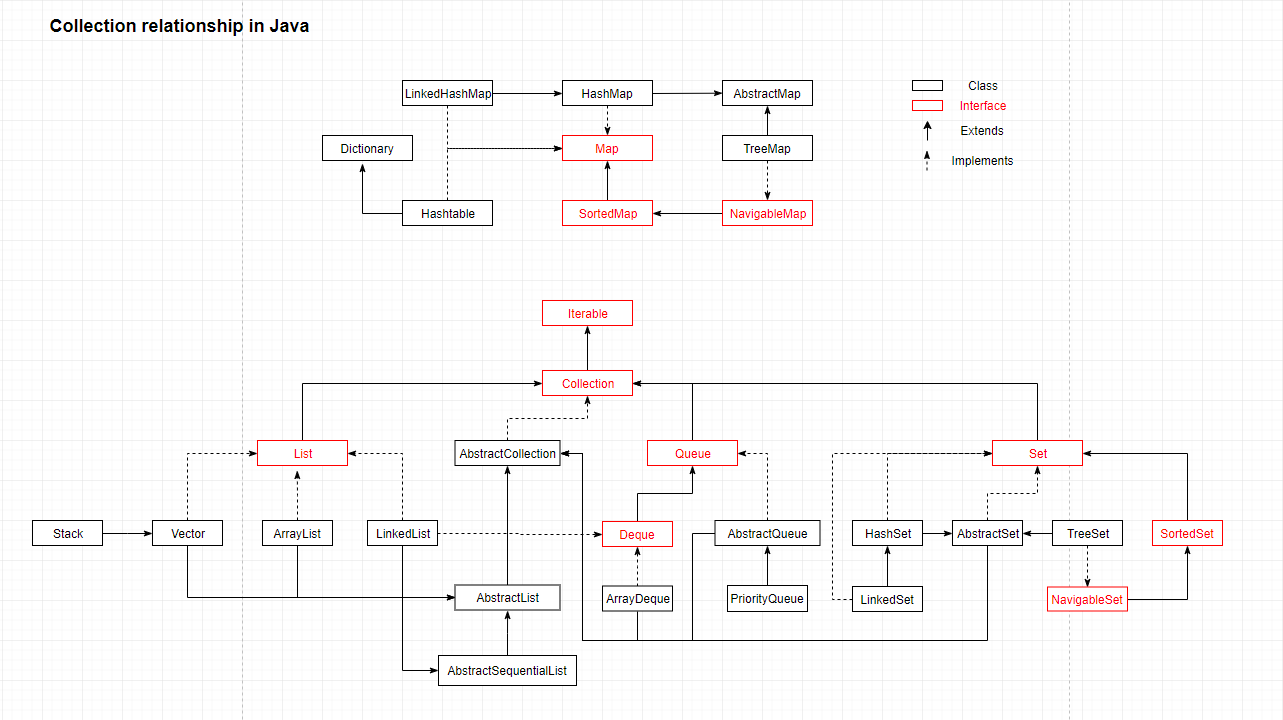
整体上集合分为 Collection 和 Map, 所有集合的实现类都要实现其中一个。
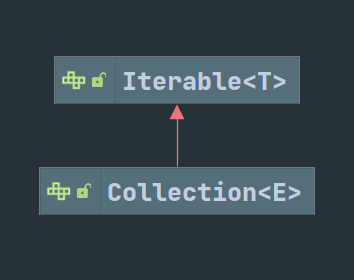
Collection
意为可迭代的。主要提供集合的迭代功能。
Iterable 源码逻辑很简单,仅包含三个方法:
创建迭代器 (Iterator)、实现foreach的方法(注意使用时容易出现 checkForComodification)以及在 jdk8 引入的供Stream使用的并行迭代器 (Spliterator)。每个实现了这个接口的实现类都必须实现自己的迭代器。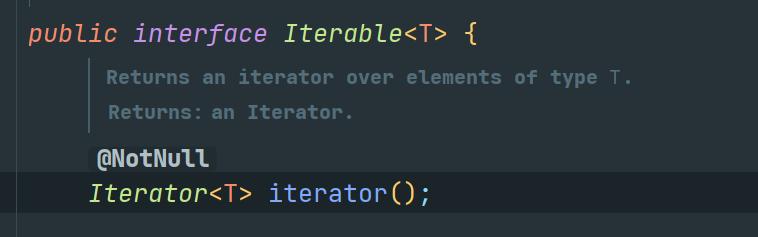
提供集合的基本功能方法,包括size、contains、add、remove、empty等。
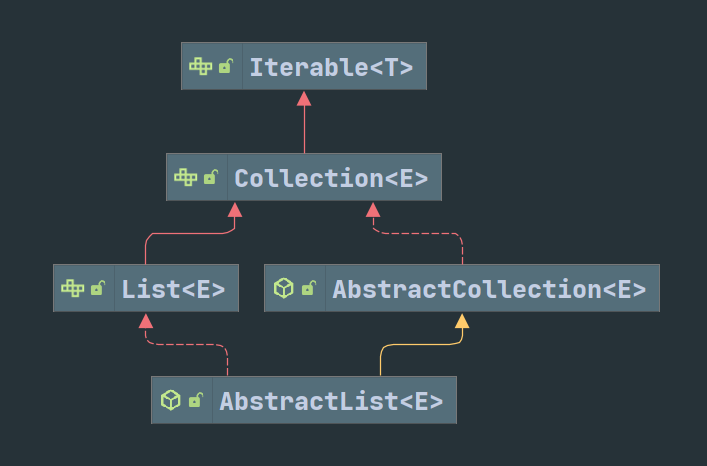
List直接继承自Collection,所以包含Collection的全部接口,但同时List也是有序容器,所以有自己特有的一些方法,主要是对容器中指定位置元素的操作。AbsrtactList实现了List的大部分接口以及来自Iterable的 Iterator () 方法。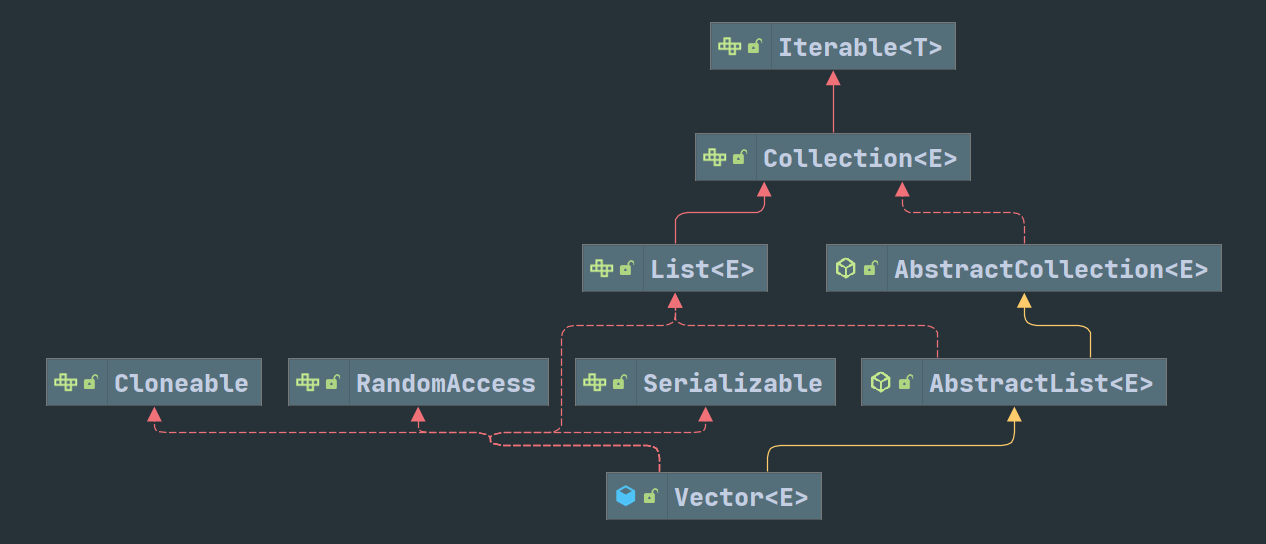
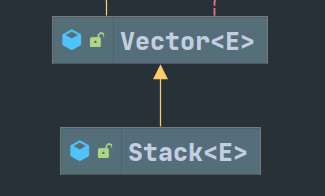
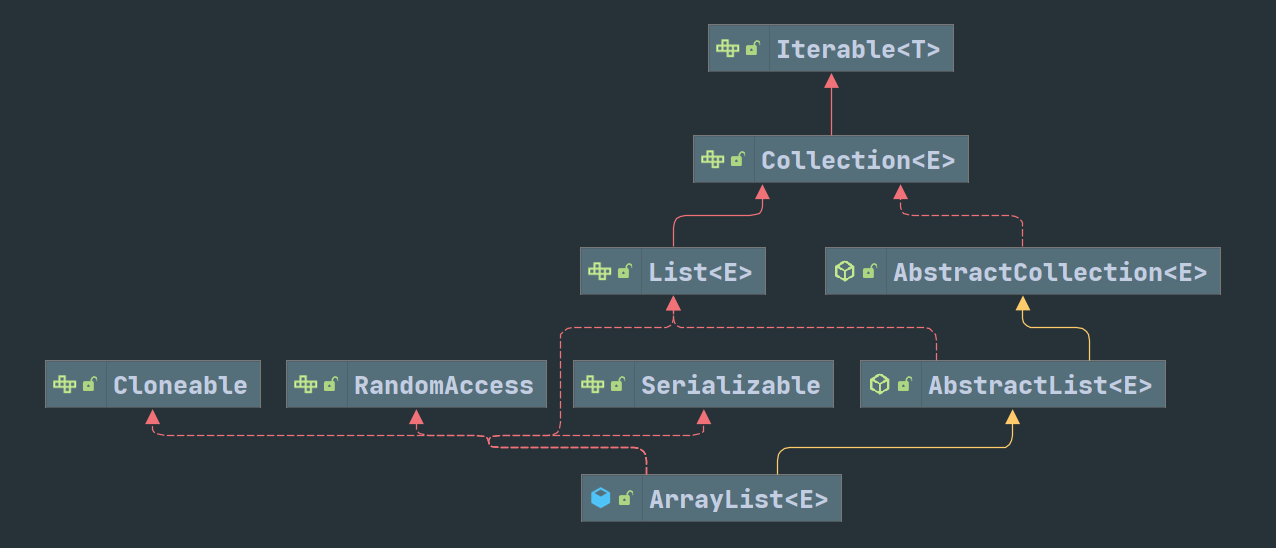
Vector、Stack和ArrayList底层都是可增长的对象数组。Vector初始化时可以指定初始容量(默认 10)和扩容数量(默认当前容量),数组在对象初始化时初始化。每次增加元素时,检查当前数组已满,如果满则按旧的数组长度扩容,如果扩容后的数组长度还是不足以装下所有元素,则新数组长度按更大的值算。每次删除指定元素时,都会生成新的数组。ArrayList的逻辑大部分与Vector相同。不同点在于,ArrayList初始化时不会初始化数组,并且ArrayList的扩容因子固定在 1.5 不能变动。
最重要的一点是Vector的方法都被 Post not found: Synchronized 修饰,这意味着Vector相比ArrayList是线程安全的,但是访问速度也更慢。Stack是直接继承自Vector的类,公有方法也都被Post not found: Synchronized 修饰。
考点:
1)为什么推荐使用ArrayList而非Vector?
在不需要考虑线程安全的情况下,由于Vector方法都被 Post not found: Synchronized 修饰ArrayList拥有更好的效率。并且Vector默认扩容一倍,比ArrayList占有更多的空间。
从历史原因来看,Vector 是 jdk1.0 的产物,后续的 jdk 需要兼容 Vector。
如果需要保证线程安全,Collections. SynchronizedList ()可以让 ArrayList 变得线程安全。
那么问题来了,Post not found: Collections. SynchronizedList ()、CopyOnWriteArrayList 与 Vector 有什么区别?
2)ArrayList有哪些优缺点?
由于 ArrayList 底层是数组,它的优点在于随机访问和顺序添加元素。
缺点也很明显,指定位置删除或添加元素时,需要重新生成数组,耗费性能。
3)为什么推荐使用Deque而非Stack?
Deque 作为双端队列,可以实现 Stack 的先进后出的功能,同时 Stack 继承自 Vector 效率较低。HashSet 的继承关系如下:
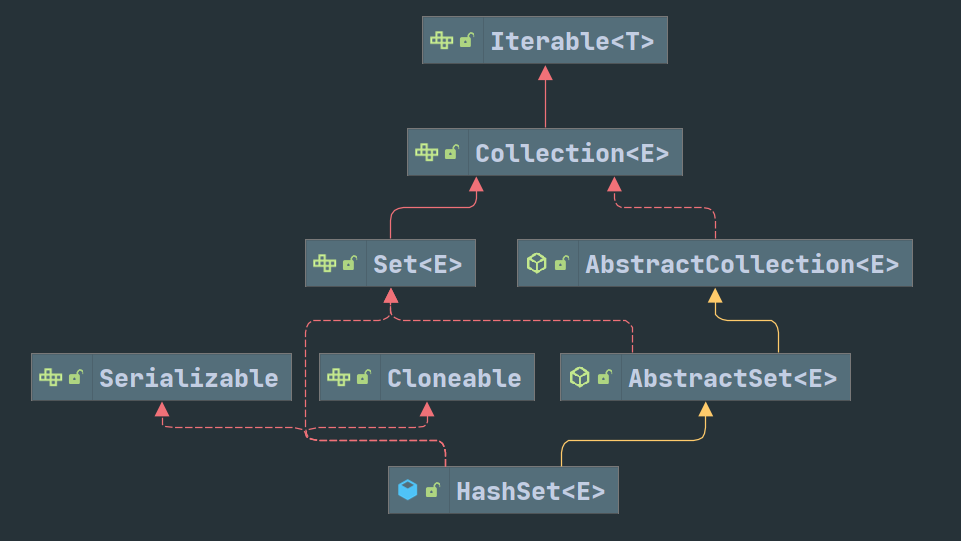
需要额外说明的一点是 AbstractSet 重写了三个方法:equal ():依次比较地址、类型、元素个数、每个元素(重写自 Object)。hashCode ():将所有元素的 hashcode 都加上(重写自 Object)。removeAll ():增加了一个判断,如果要删除的集合元素个数比原集合少,则改为遍历要删除的集合,尝试在在原集合中删除(遍历查找)。(重写自AbstractCollection)HashSet内部使用HashMap保存数据。相关操作参考HashMap。TreeSet的情况也是如此,内部使用TreeMap保存数据。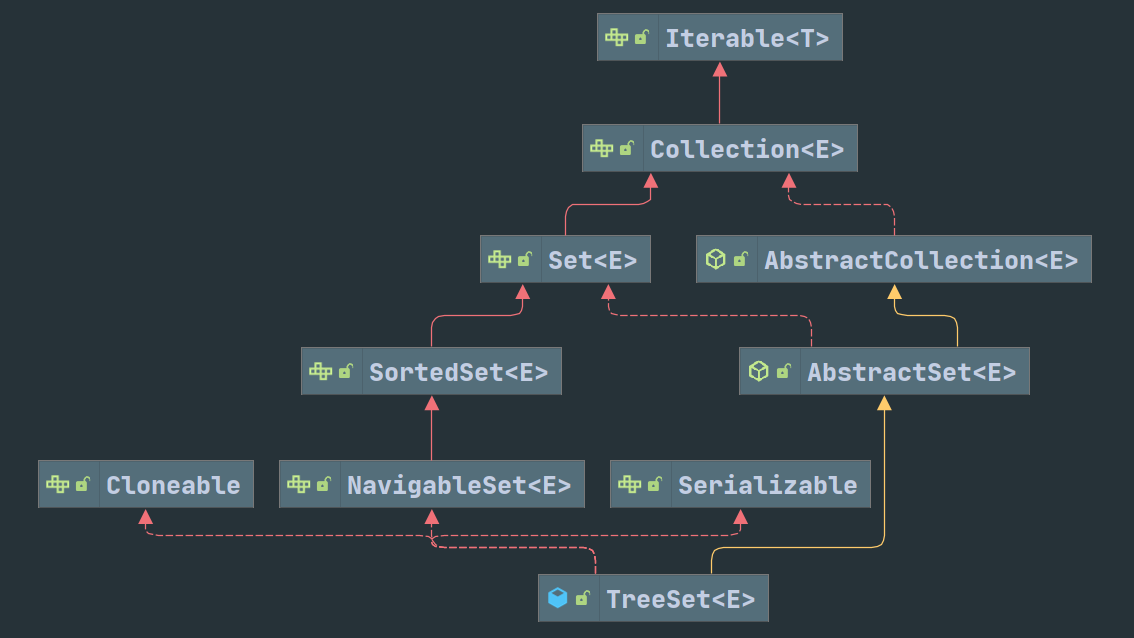
不过 LinkedHashSet 的情况比较特殊。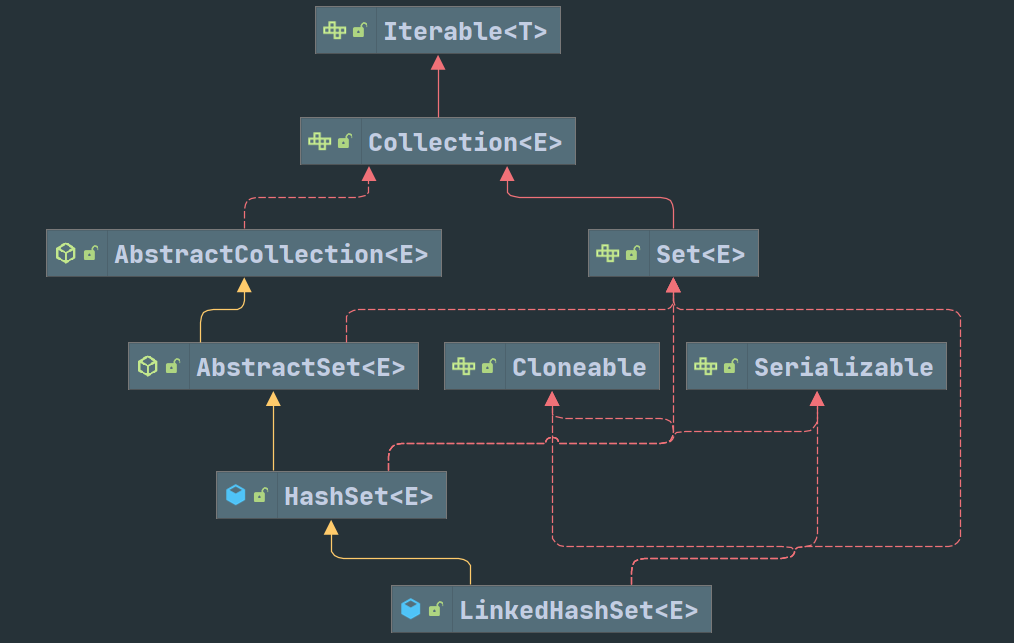
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26public class LinkedHashSet<E> extends HashSet<E> implements Set<E>, Cloneable, java.io.Serializable {
private static final long serialVersionUID = -2851667679971038690L;
public LinkedHashSet(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor, true);
}
public LinkedHashSet(int initialCapacity) {
super(initialCapacity, .75f, true);
}
public LinkedHashSet() {
super(16, .75f, true);
}
public LinkedHashSet(Collection<? extends E> c) {
super(Math.max(2*c.size(), 11), .75f, true);
addAll(c);
}
public Spliterator<E> spliterator() {
return Spliterators.spliterator(this, Spliterator.DISTINCT | Spliterator.ORDERED);
}
}表面上
LinkedHashSet只继承自HashSet。代码也非常简单。
但构造方法调用了HashSet专门准备的构造方法:1
2
3HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}所以在创建的时候实际创建的时 LinkedHashMap。
EnumSet是抽象类,应用场景为集合参数是枚举值。
Post not found: PriorityQueue(优先队列)实现了Post not found: 小根堆 堆。Queue(队列) 需要满足可以从队尾添加元素并从头部删除。DeQeque(双端队列) 需要满足从头尾都可以添加和删除元素, 但不允许从中间添加元素。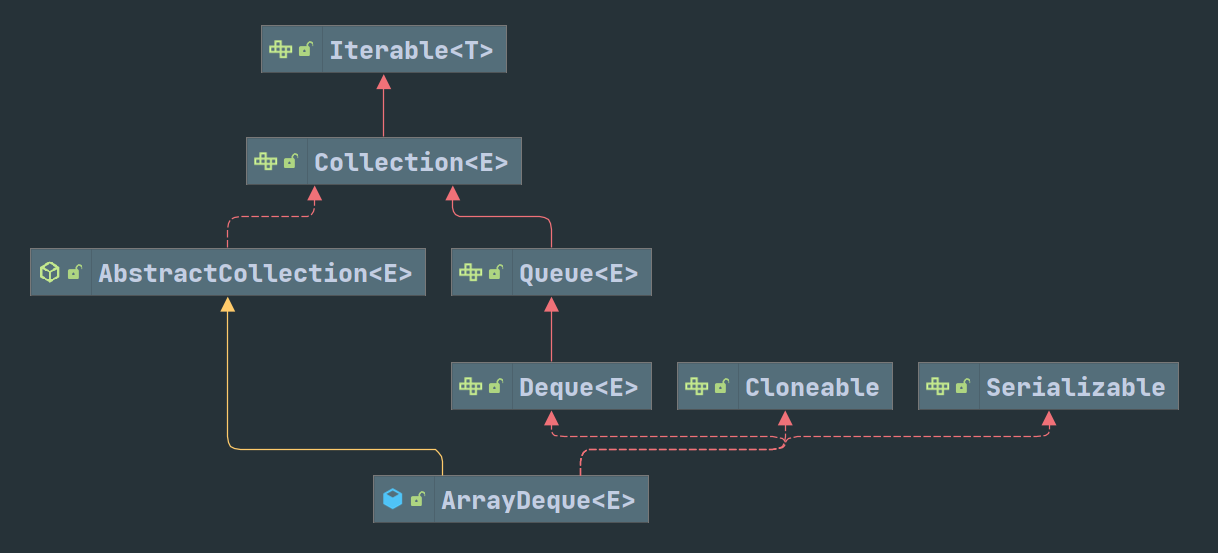
ArrayDeque是常见的双端队列,底层数据结构是数组,通过分别指向首尾的两个索引控制队列。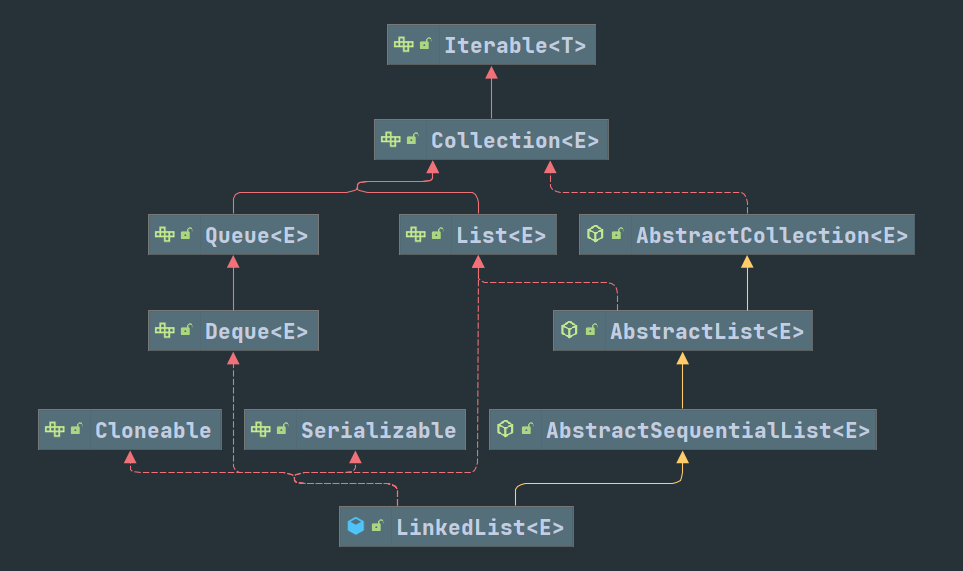
LinkedList同时拥有List和Deque的属性。底层数据结构是链表,两个指针分别指向链表的首部和尾部。保证可以LinkedList从首部和尾部均可操作元素。Map
与
Collection不同,Map是由多个键值映射组成的,Map 映射中不能存在重复的键。
提供返回键集(即 Set)、值集(即 Collection)、键值映射集(即键值 Set 集合)。
其中比较重要的实现类是 Post not found: HashMap、Post not found: LinkedHashMap、Post not found: HashTable、Post not found: TreeMap、ConcurrentHashMap、Post not found: WeakHashMap。

